工作到现在,做过一些系统的数据库设计,当在被问到如何使用范式来设计的时候,其实我是懵逼的。然而在自己查过资料以后,对范式的理解其实和自己潜意识中的设计经验是一致的。在对索引的优化的经验中,了解了下何为索引、索引的结构、索引的使用、及索引的优化方式也有了一点总结,也了解了下MySQL内部的执行及优化过程。
SCHEMA设计
范式:一张数据表的表结构所符合的某种设计标准的级别
1NF/2NF/3NF/BCNF/4NF/5NF,一般最多到BCNF就够。
1NF
1NF:符合1NF的关系中的每个属性都不可再分,是关系型数据库的最基本要求。最小属性只能是一个值,不能被拆分成多个字段,否则的话,它就是可分割的,就不符合一范式。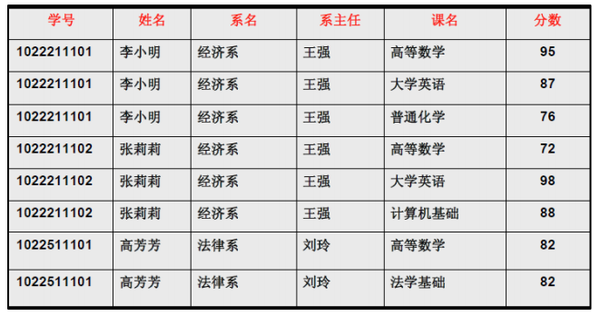
可能导致的问题
- 1.数据冗余过大,针对上表某一学生的学号、姓名、系名、对应的系主任等数据重复多次
- 2.插入异常,新建了某个系无法将系主任对应到相应的系中
- 3.删除异常,将学生信息删除,系名、系主任也被删除
- 4.修改异常,小明转系,多条数据都要被修改
2NF
2NF: 在1NF的概念基础上,消除了非主属性对于码的部分函数依赖。通俗的说,根据主键将数据表的各依赖关系解耦。就是要有主键,要求其他字段都依赖于主键。
依上表可以将表关系拆为: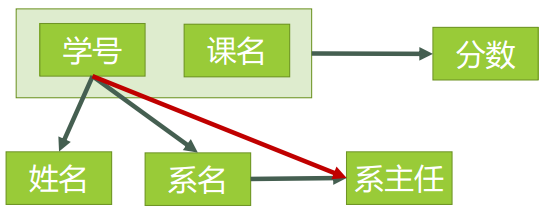
模式分解以后的新数据为下图: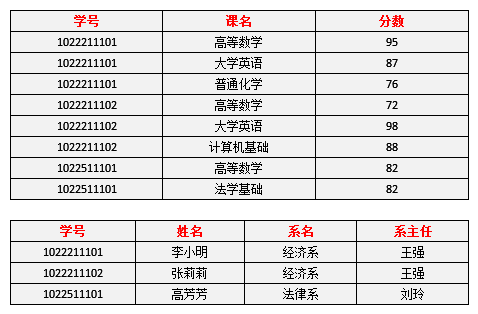
由上图可以看出,删除异常及增加系信息仍无改进。
3NF
3NF:3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。就是要消除传递依赖,方便理解,可以看做是“消除冗余”。
在上图的基础上,可进一步拆解为以下关系: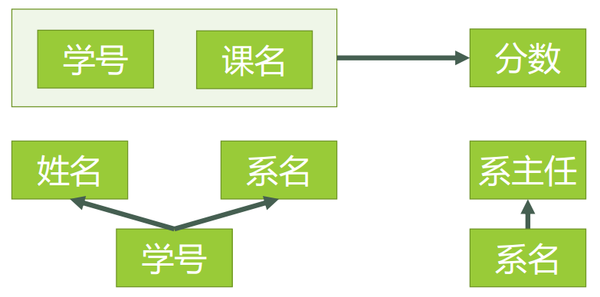
分解后的新数据为: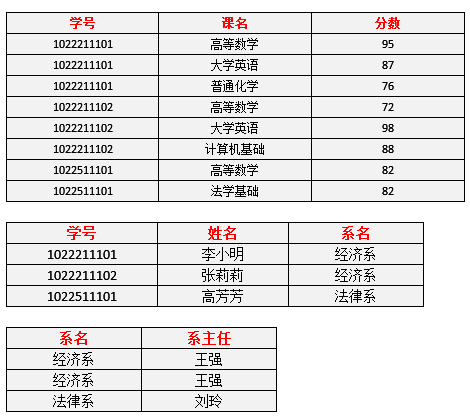
已经看出上述的数据冗余问题已经消除了。
BCNF
BCNF:在满足第二第三范式的情况下,主属性内部也不能部分或传递依赖。判断方法:箭头左边的必须是候选码,不是候选码的就不是BC范式。
举个例子:如学号、学生名字、学生QQ,设置学号为主键,但是qq、名字都可作为候选键,不符合BC范式。
解决的方案是保留一个候选键为主键,从而保证每个表中只有一个候选键。
一般的系统设计到第三范式就可以满足了,BC范式太苛刻,大多数情况用不到。
加快ALTER TABLE的操作速度
Mysql的ALTER TABLE操作的性能对大表来说是个很大的问题,会导致服务中断,因为涉及到索引结构的变更。有以下两个技巧可以避免:
- 在一台不提供服务的机器上执行操作,然后和提供服务的主库进行切换。
- 先建立一张临时表,通过重命名和删表的操作来交换。
CHAR和VARCHAR
VARCHAR
- 用于存储可变长字符串,比定长类型更节省空间。
- 需要额外的1或2个额外字节记录字符串长度,如果列的最大长度小于或者等于255字节,则只使用1个字节表示,否则使用 2 个字节。
- 节省了存储空间,所以对性能也有帮助。但是,行变长时,如果页内没有更多的空间可以存储,MyISAM 会将行拆成不同的片段存储,InnoDB 则需要分裂页来使行可以放进页内。
每页最多能存多少数据? 2^8 = 256, 2^16 = 65536。数据能否超过65536?如果不能,超过了会怎么样?– MySQL 中 VARCHAR 类型的最大长度限制为 65535。
CHAR
- 定长,根据定义分配足够的空间。当存储 CHAR 值时,MySQL 会删除所有的末尾空格。CHAR 值会根据需要采用空格进行填充以方便比较。
- CHAR适合存储很短的字符串,或者所有值都接近同一个长度,比如密码的MD5值。
- 对于经常变更的数据, CHAR 也比 VARCHAR 更好,定长不容易产生碎片。
- 非常短的列, CHAR 比 VARCHAR 在存储空间上更有效率。
索引
概念:索引优化应该是对查询性能优化最有效的手段。可以轻松提高几个数量级。
存储金字塔
计算机中最重要的存储介质分为几类:硬盘、内存、二级缓存、寄存器。它们之间的对比如下:
从上面的图中,我们可以看出,从下往上,速度从慢到快,制造成本也越来越高。几种有代表性的存储设备的典型访问速度如下:
从图中大概可以看出:高速缓存的访问速度是主存的10~100倍,而主存的速度则是硬盘的1~10W倍,完全不是一个数量级的。
索引结构
B+Tree
- 只有最底层的节点(叶子节点)才保存信息
- 其他节点只是在搜索中用来指引到正确的节点

B+树种的B不是代表二叉(binary),而是代表平衡(balance),因为 B+树是从最早的平衡二叉树演化而来,但是 B+树不是一个二叉树。
哈希表
构建一个哈希表需要以下定义:
- 元素的关键字
- 关键字的哈希函数。关键字计算出来的哈希值给出了元素的位置(叫做哈希桶)。
- 关键字比较函数。通过找到的正确哈希桶,在比较函数内找到要的函数。

好的哈希函数在哈希桶里面包含非常少的元素,时间复杂度是O(1)。
InnoDB逻辑存储结构
所有数据都被逻辑的存放在一个空间中,称为表空间。表空间由段、区、页组成,页也有在一些文档中被称为块。
InnoDB存储引擎是面向列的,数据是按行进行存放的。每个页存放的记录是有硬性规定,最多允许存放16KB~2-200行的记录,即7992行。
索引类型
B-Tree索引
NDB集群存储引擎内部使用了T-Tree,InnoDB则使用了B+Tree。MyISAM使用前缀压缩技术使索引更小。B-Tree通常认为所有的只都是按顺序存储的,并且每个叶子节点到根的距离相同,之所以能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描,而是从索引的根节点开始搜索。
叶子节点比较特别,他们的指针指向的是被索引的数据,而不是其他的节点页。B-Tree 对索引列是顺序组织存储的,所以很适合查找范围数据。
B-Tree使用限制
- 如果不是按照索引的最左列开始查找,则无法使用索引。
- 不能跳过索引中的列。
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。
B+树索引并不能找到一个给定键值的具体行。B+树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
自增ID的使用是为了解决页分裂的问题,一页总要被存满,然后新开一页继续,这种行为称为页分裂,mysql规定一个分裂因子,达到存储空间的15/16就存到下一页,页分裂会极大的影响维护索引的性能,故通常设定一个无意义的整数自增索引,有利于索引存储。如果是非自增或非整数,作为索引值,新增数据时需要寻找合适的位置,会在之前的页中插入,导致该页达到分裂因子的阀值引起索引页的分裂,索引文件发生变化,数据量大会浪费大量时间,产生碎片。
索引的优点:
- 索引大大减少了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机 I/O 变为顺序 I/O 。
聚簇索引
数据行存放在索引的叶子页中,数据行和相邻的键值紧凑的存储在一起。
优点:
- 相关数据保存在一起。
- 数据访问更快。索引和数据保存在同一个b-tree中,查询数据比非聚簇索引快。
缺点:
- I/O密集型应用,对于内存存储没有优势。
- 插入速度严重依赖插入顺序。
- 更新索引代价高,主键更新导致需要移动行的时候,面临页分裂,会占用更多磁盘空间。
- 可能导致全表扫描变慢,行比较稀疏、页分裂导致数据存储不连续的时候。
MyISAM和InnoDB数据分布
MyISAM
1.主键叶子节点存放数据行的指针。
2.主键和其他索引没有区别。
InnoDB
聚簇索引每一个叶子节点都包含了主键值、事务ID/MVCC回滚指针及剩余列。
在InnoDB表中按主键顺序插入行,对于主键做关联的操作性能会更好。
查询性能优化
为什么会查询慢?
查询的生命周期大致可以按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端。在完成这些任务的时候,查询需要在不同的地方花费时间,包括网络,CPU 计算,生成统计信息和执行计划、锁等待(互斥等待)等操作,尤其是向底层存储引擎检索数据的调用,这些调用需要在内存操作、CPU 操作和内存不足时导致的 I/O 操作上消耗时间。
衡量查询开销的三个指标:
- 响应时间
- 扫描的行数
- 返回的行数
这三个指标可在Mysql的慢日志中查到,扫描行数过多可于此找出。
响应时间
响应时间由两部分之和:服务时间+排队时间。
服务时间:数据库处理这个查询真正花了多少时间。
排队时间:指服务器因为等待某些资源而没有真正执行查询的时间—可能是等 I/O 操作完成,也可能是等待行锁等待。
一般最常见和重要的等待是 I/O 和锁等待。
扫描的行数和返回的行数
并不是所有的行的访问代价是相同的。较短的行的访问速度更快,内存中的行也比磁盘中的行的访问速度要快得多。
理想情况下扫描的行数和返回的行数应该是相同的。扫描的行数对返回的行数比率通常很小,一般在 1:1 和 10:1 之间。
扫描的行数和访问类型
在评估查询开销的时候,需要考虑一下从表中找到某一行数据的成本。
在 EXPLAIN 语句中的 type 列反应了访问类型。访问类型有很多种,从全表扫描到索引扫描、范围扫描、唯一索引查询、常数引用等。
重构查询的方式
- 一个复杂查询还是多个简单查询
- 切分查询
- 分解关联查询
查询执行的基础
从客户端输入查询请求,到服务器返回查询结果,mysql的执行过程如下:
执行的主要操作如下:
1.客户端发送一条查询给服务器。
2.服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。
3.服务器进行 SQL 解析、预处理,再由优化器生成对应的执行计划。
4.MySQL 根据优化器生成的执行计划,调用存储引擎的 API 来执行查询。
5.将结果返回给客户端。
查询状态
对于一个MySQL连接,或者是一个线程,任何时刻都有一个状态,表示了MySQL当前正在做什么,可以用SHOW FULL PROCESSLIST查看。
- Sleep
线程正在等待客户端发送新的请求。
- Query
线程正在执行查询或者正在将结果发送给客户端。
- Locked
在 MySQL 服务器层,该线程正在等待表锁。在存储引擎级别实现的锁,例如 InnoDB 的行锁,并不会体现在线程状态中。
- Analyzing and statistics
线程正在收集存储引擎的统计信息,并生成查询的执行计划。
- Copying to tmp table [on disk]
线程正在执行查询,并且将结果集都复制到一个临时表中,这种状态一般要么是在做 GROUP BY 操作,要么是文件排序操作,或者是 UNION 操作。如果这个状态后面还有 on disk 标记,那表示 MySQL 正在将一个内存临时表放到磁盘上。
- Sorting result
线程正在对结果集进行排序。
- Sending data
这表示多种情况:线程可能在多个状态之间传送数据,或者在生成结果集,或者在向客户端返回数据。
查询缓存
解析查询语句之前,查询缓存是打开的话,会优先查询命中缓存中的数据。检查是通过对大小写敏感的哈希查找实现的。
查询优化处理
将SQL转换成一个执行计划,MySQL再将执行计划和存储引擎交互,包括:解析SQL、预处理、优化SQL执行计划。
语法解析器和预处理
MySQL通过关键字解析SQL语句,生成对应的“解析树”,MYSQL解析器验证语法规则和解析查询。预处理根据MySQL规则进一步检查解析树是否合法。下一步预处理器验证权限。查询优化器
一条查询有多种执行方式,最终返回一样的结果。
排序优化
排序是一个成本很高测操作,从性能考虑,需要避免对大量数据进行排序。
排序的数量小于“排序缓冲区”,MySQL使用内存进行“快速排序”。内存不够,则先将数据分块,对独立块进行“快速排序”,在对子结果进行合并。
MySQL EXPLAIN详解
| select_type | parititons | type | possible_keys | key | key_len | ref | rows | filtered | extra |
|---|---|---|---|---|---|---|---|---|---|
- type
这是重要的列,显示使用了何种连接类型。从最好到最差的连接类型为system、const、eq_ref、ref、range、index和all。
- possible_keys
显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从where语句中选择一个合适的语句。
- key
实际使用的索引。如果为null,则没有使用索引。很少的情况下,mysql会选择优化不足的索引。这种情况下,可以在select语句中使用use index(indexname)来强制使用一个索引或者用ignore index(indexname)来强制mysql忽略索引
- key_len
使用的索引的长度。在不损失精确性的情况下,长度越短越好
- ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
- rows
mysql认为必须检查的用来返回请求数据的行数,影响的行数越小或是1的才没问题
- extra
关于mysql如何解析查询的额外信息。但这里可以看到的坏的例子是using temporary和using filesort,意思mysql根本不能使用索引,结果是检索会很慢。
参考资料
- 地瓜哥 《MySQL学习笔记》 http://notes.diguage.com/mysql/
- 知乎 《解释一下数据库的第一第二第三范式》 https://www.zhihu.com/question/24696366
- 《高性能MySQL》
- 《MySQL技术内幕》